标准差公式
 标准差公式详解
标准差公式详解
标准差(Standard Deviation)是统计学中用于衡量数据离散程度的核心指标,反映数据点与均值之间的平均距离。其计算过程分为总体标准差和样本标准差两种,核心公式如下:
1. 总体标准差(Population Standard Deviation)
当数据代表整个总体时,使用总体标准差公式:
[
sigma = sqrt{frac{1}{N} sum_{i=1}^{N} (x_i – mu)^2}
]
符号说明:
– (sigma):总体标准差
– (N):总体数据量
– (x_i):第(i)个数据点
– (mu):总体均值((mu = frac{1}{N} sum x_i))
计算步骤:
1. 计算均值:求所有数据点的平均值(mu)。
2. 求偏差平方:每个数据点与均值的差((x_i – mu)),然后平方。
3. 计算方差:取偏差平方的平均值((frac{1}{N} sum (x_i – mu)^2))。
4. 开平方:对方差取平方根,得到标准差。
示例:
数据集 ([2, 4, 6, 8])
– 均值 (mu = 5)
– 偏差平方和 (= (2-5)^2 + (4-5)^2 + (6-5)^2 + (8-5)^2 = 20)
– 方差 (sigma^2 = 20 / 4 = 5)
– 标准差 (sigma = sqrt{5} approx 2.24)
2. 样本标准差(Sample Standard Deviation)
当数据为总体的一部分样本时,使用样本标准差公式(分母为(n-1),修正自由度):
[
s = sqrt{frac{1}{n-1} sum_{i=1}^{n} (x_i – bar{x})^2}
]
符号说明:
– (s):样本标准差
– (n):样本量
– (bar{x}):样本均值((bar{x} = frac{1}{n} sum x_i))
修正原因:
分母使用(n-1)(贝塞尔校正)可避免低估总体方差,因样本均值(bar{x})本身已拟合数据,导致偏差平方和较小。
3. 关键概念解析
– 方差 vs 标准差:方差((sigma^2)或(s^2))是标准差的平方,但标准差与原始数据单位一致,更直观。
– 离散程度:标准差越大,数据分布越分散;越小则越集中。
– 正态分布:约68%数据落在均值±1标准差内,95%在±2标准差内(经验法则)。
4. 应用场景
– 金融:衡量投资风险(如股票收益波动)。
– 质量控制:检测产品尺寸的稳定性。
– 科研:分析实验数据的可靠性。
5. 注意事项
– 异常值敏感:极端值会显著增大标准差。
– 单位一致性:标准差单位与数据相同(如厘米、千克)。
– 分布类型:适用于对称分布(如正态分布),偏态分布需结合其他指标。
总结
标准差通过量化数据波动性,为数据分析提供基础工具。正确区分总体与样本公式,理解其背后的统计意义,是应用的关键。实际计算中,可借助Excel(`STDEV.P`/`STDEV.S`)或Python(`numpy.std`)快速实现。
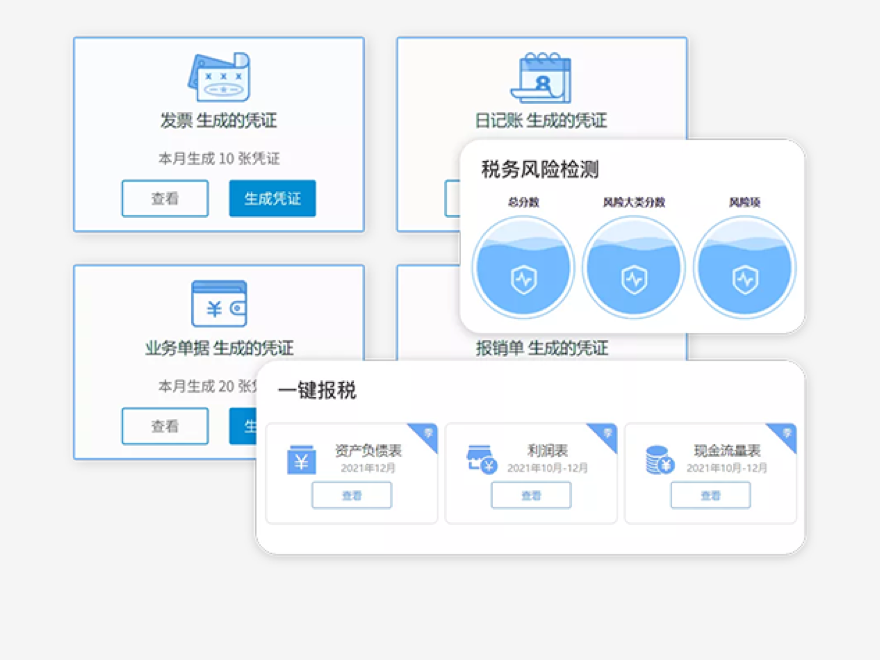
点击右侧按钮,了解更多行业解决方案。
相关推荐
标准差公式excel
标准差公式excel
标准差公式在Excel中的应用
标准差是统计学中衡量数据离散程度的重要指标,Excel提供了多种计算标准差的函数。本文将详细介绍Excel中标准差的计算方法、适用场景以及实际应用技巧。
一、标准差的统计学意义
标准差(Standard Deviation)反映一组数据相对于平均值的离散程度。标准差越大,表示数据点分布越分散;标准差越小,表示数据点越集中于平均值附近。
标准差的计算公式为:
```
σ = √[Σ(xi - μ)2/N]
```
其中:
- σ:总体标准差
- xi:数据集中的每个值
- μ:数据集的平均值
- N:数据集中的数据个数
二、Excel中的标准差函数
Excel提供了6个与标准差相关的函数,适用于不同场景:
1. STDEV.P函数
计算基于整个样本总体的标准差(忽略逻辑值和文本)。
语法:`=STDEV.P(number1,[number2],...)`
2. STDEV.S函数
计算基于样本估算的标准差(忽略逻辑值和文本)。
语法:`=STDEV.S(number1,[number2],...)`
3. STDEVA函数
计算基于样本估算的标准差,包含逻辑值和文本的表示形式(TRUE=1,FALSE=0,文本=0)。
语法:`=STDEVA(value1,[value2],...)`
4. STDEVPA函数
计算基于整个样本总体的标准差,包含逻辑值和文本的表示形式。
语法:`=STDEVPA(value1,[value2],...)`
5. 旧版函数STDEV(兼容性函数)
与STDEV.S功能相同,为保持与旧版本兼容而保留。
6. 旧版函数STDEVP(兼容性函数)
与STDEV.P功能相同,为保持与旧版本兼容而保留。
三、STDEV.P与STDEV.S的区别
1. 适用场景不同:
- STDEV.P用于计算总体标准差(当数据代表整个总体时)
- STDEV.S用于计算样本标准差(当数据只是总体的一个样本时)
2. 计算公式差异:
- STDEV.P分母为N
- STDEV.S分母为n-1(贝塞尔校正)
3. 结果大小:
对于同一数据集,STDEV.S计算的结果通常略大于STDEV.P
四、Excel标准差计算步骤
方法1:使用函数直接计算
1. 在空白单元格输入`=STDEV.S(`或`=STDEV.P(`
2. 选择数据区域
3. 输入右括号`)`并按回车
方法2:使用公式选项卡
1. 点击"公式"选项卡
2. 选择"其他函数"→"统计"
3. 选择相应的标准差函数
4. 在函数参数对话框中设置数据范围
五、实际应用案例
案例1:学生成绩分析
假设A2:A31区域是30名学生的数学成绩:
```
=STDEV.S(A2:A31) // 样本标准差
=STDEV.P(A2:A31) // 总体标准差
```
案例2:质量控制
在生产线质量控制中,计算产品尺寸的标准差:
```
=STDEV.P(B2:B1000) // 假设这是全天生产的所有产品
```
案例3:市场调研
调查100名消费者对产品的满意度评分(样本):
```
=STDEV.S(C2:C101) // 样本标准差
```
六、注意事项
1. 选择正确的函数:根据数据是总体还是样本选择STDEV.P或STDEV.S
2. 数据范围不应包含非数值内容(除非使用STDEVA或STDEVPA)
3. 空单元格和文本值在大多数标准差函数中会被忽略
4. 对于大数据集,计算标准差前建议先检查数据质量
5. 标准差对异常值敏感,分析时需结合其他统计量
七、标准差与其他统计量的结合使用
1. 与平均值结合:计算变异系数(CV)=标准差/平均值
2. 与正态分布结合:68-95-99.7规则(数据落在μ±σ、μ±2σ、μ±3σ内的比例)
3. 与图表结合:在柱形图或折线图中添加标准差误差线
八、常见问题解答
Q:为什么我的标准差计算结果与手工计算不同?
A:可能原因:1)使用了错误的函数;2)数据范围选择有误;3)手工计算时四舍五入误差。
Q:什么时候使用STDEVA而不是STDEV.S?
A:当数据中包含需要转换为数值的逻辑值(TRUE/FALSE)或文本数字时使用STDEVA。
Q:Excel的标准差函数能处理多大的数据量?
A:现代Excel版本可以处理数百万行数据,但超大数据集可能影响计算速度。
通过掌握Excel中的标准差计算方法,您可以更有效地分析数据变异程度,为决策提供有力支持。在实际应用中,建议根据数据特点和需求选择合适的标准差函数,并结合其他统计指标进行综合分析。
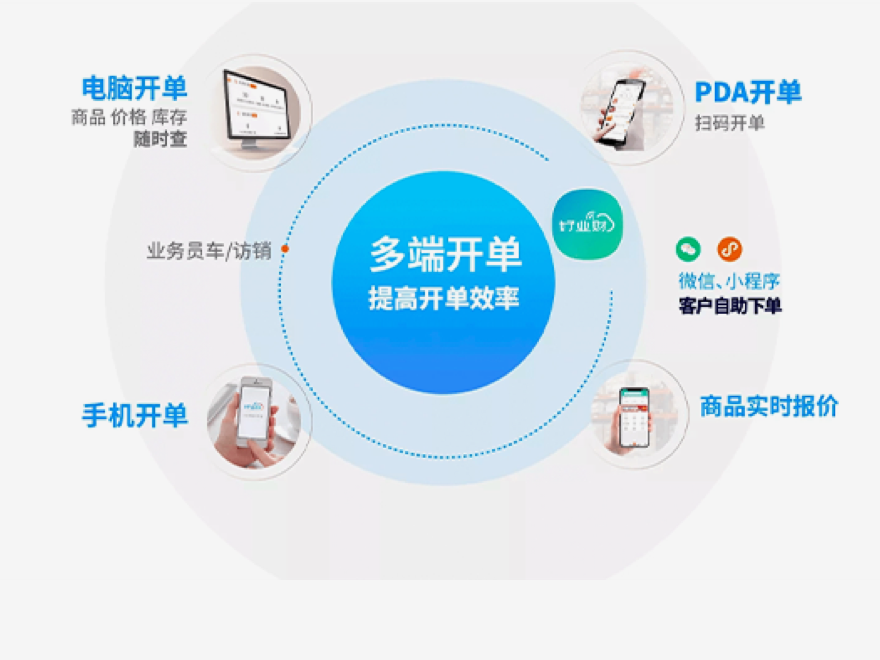
点击右侧按钮,了解更多行业解决方案。
标准差公式计算方法
标准差公式计算方法
标准差的计算方法
标准差(Standard Deviation)是统计学中用于衡量一组数据离散程度的重要指标,反映了数据点与平均值之间的平均距离。标准差越大,表示数据分布越分散;标准差越小,表示数据分布越集中。以下是标准差的计算方法及其步骤的详细说明。
一、标准差的基本概念
标准差是方差的算术平方根,而方差是每个数据点与均值之差的平方的平均值。标准差的计算分为以下两种情况:
1. 总体标准差:当数据涵盖整个研究对象时使用,公式为:
[
sigma = sqrt{frac{1}{N} sum_{i=1}^{N} (x_i - mu)^2}
]
其中:
- (sigma):总体标准差;
- (N):总体数据量;
- (x_i):第(i)个数据点;
- (mu):总体均值((mu = frac{1}{N} sum_{i=1}^{N} x_i))。
2. 样本标准差:当数据是总体的一个样本时使用,公式为:
[
s = sqrt{frac{1}{n-1} sum_{i=1}^{n} (x_i - bar{x})^2}
]
其中:
- (s):样本标准差;
- (n):样本数据量(通常 (n < N)); - (bar{x}):样本均值((bar{x} = frac{1}{n} sum_{i=1}^{n} x_i))。 注意:样本标准差的分母为(n-1)(称为贝塞尔校正),用于更准确地估计总体标准差。 二、标准差的计算步骤 以计算样本标准差为例,具体步骤如下: 1. 计算均值((bar{x})) 将所有数据相加后除以数据量: [ bar{x} = frac{x_1 + x_2 + cdots + x_n}{n} ] 2. 计算每个数据点的离差((x_i - bar{x})) 每个数据点减去均值,得到其与均值的偏差。 3. 计算离差的平方(((x_i - bar{x})^2)) 平方的目的是消除负值并放大较大偏差的影响。 4. 计算方差((s^2)) 将所有离差平方求和后除以(n-1): [ s^2 = frac{sum_{i=1}^{n} (x_i - bar{x})^2}{n-1} ] 5. 计算标准差((s)) 对方差取算术平方根: [ s = sqrt{s^2} ] 三、实例演示 假设有一组样本数据:([2, 4, 6, 8]),计算其标准差。 1. 计算均值: [ bar{x} = frac{2 + 4 + 6 + 8}{4} = 5 ] 2. 计算离差平方: [ (2-5)^2 = 9, quad (4-5)^2 = 1, quad (6-5)^2 = 1, quad (8-5)^2 = 9 ] 3. 计算方差: [ s^2 = frac{9 + 1 + 1 + 9}{4-1} = frac{20}{3} approx 6.67 ] 4. 计算标准差: [ s = sqrt{6.67} approx 2.58 ] 四、注意事项 1. 区分总体与样本: 使用总体标准差时,分母为(N);样本标准差分母为(n-1)。 2. 单位一致性: 标准差的单位与原始数据一致(如数据单位为“米”,标准差也是“米”)。 3. 极端值影响: 标准差对异常值敏感,极端值会显著增大标准差。 五、标准差的应用 1. 衡量数据波动性: 在金融中,标准差用于评估投资风险;在质量控制中,用于检测生产稳定性。 2. 正态分布分析: 约68%的数据落在均值±1标准差内,95%在±2标准差内(经验法则)。 通过理解标准差的计算方法和意义,可以更科学地分析数据的分布特征,为决策提供依据。
点击右侧按钮,了解更多行业解决方案。
标准差公式SD
标准差公式SD
标准差(Standard Deviation)公式详解
一、标准差的定义
标准差(SD)是衡量数据离散程度的核心指标,反映数据点与均值(μ)的平均距离。其数值越大,数据分布越分散;数值越小,数据越集中。标准差分为总体标准差(σ)和样本标准差(s),两者计算略有差异。
二、标准差的计算公式
1. 总体标准差(σ)
适用于数据为全集时:
[
sigma = sqrt{frac{1}{N} sum_{i=1}^{N} (x_i - mu)^2}
]
- ( N ):总体数据量
- ( x_i ):第i个数据点
- ( mu ):总体均值
2. 样本标准差(s)
适用于从总体中抽取样本时(使用贝塞尔校正,分母为( n-1 )):
[
s = sqrt{frac{1}{n-1} sum_{i=1}^{n} (x_i - bar{x})^2}
]
- ( n ):样本量
- ( bar{x} ):样本均值
三、计算步骤(以样本标准差为例)
1. 计算均值:
[
bar{x} = frac{1}{n} sum_{i=1}^{n} x_i
]
2. 求偏差平方和:
每个数据点与均值的差(( x_i - bar{x} )),平方后求和。
3. 计算方差:
偏差平方和除以( n-1 )(样本方差)。
4. 开平方:
对方差取平方根,得到标准差。
四、实例演示
数据集:[ 2, 4, 6, 8 ](假设为样本)
1. 均值:( bar{x} = (2+4+6+8)/4 = 5 )
2. 偏差平方和:
[
(2-5)^2 + (4-5)^2 + (6-5)^2 + (8-5)^2 = 9 + 1 + 1 + 9 = 20
]
3. 样本方差:( s^2 = 20/(4-1) approx 6.67 )
4. 样本标准差:( s = sqrt{6.67} approx 2.58 )
五、标准差的意义
1. 数据分布分析:
- 68%数据落在( mu pm sigma )内(正态分布)。
- 95%数据在( mu pm 2sigma )内。
2. 比较数据集的离散度:如A组SD=1.5,B组SD=3.0,则B组更分散。
3. 风险评估:金融中用于衡量收益波动性。
六、注意事项
1. 区分总体与样本:样本标准差分母为( n-1 ),避免低估总体方差。
2. 异常值影响:标准差对极端值敏感,需结合箱线图等分析。
3. 单位一致性:标准差的单位与原始数据相同。
七、与其他指标的关系
- 方差:标准差的平方(( sigma^2 )),但单位不同。
- 极差:仅用最大值-最小值,忽略中间数据分布。
- 四分位距:基于中位数,对异常值不敏感。
八、应用场景
1. 质量控制:监测生产数据稳定性。
2. 投资分析:评估股票波动风险。
3. 学术研究:比较实验组与对照组的差异显著性。
九、常见误区
1. 误用总体公式:样本数据未调整分母导致偏差。
2. 忽视分布形态:非正态分布中,标准差解释力下降。
3. 混淆标准差与标准误差:后者反映均值抽样误差。
十、总结
标准差通过量化数据波动性,为统计分析提供基础工具。正确应用需理解其假设条件(如正态性)及计算细节(如贝塞尔校正),并结合其他统计量(如均值、中位数)全面解读数据。
点击右侧按钮,了解更多行业解决方案。
免责声明
本文内容通过AI工具智能整合而成,仅供参考,e路人不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系1224598712@qq.com进行反馈,e路人收到您的反馈后将及时答复和处理。